
So for the past weeks I’m troubleshooting a Sophos UTM 9.4 cluster which won’t come into sync with each other. We’re migrating VM’s from one Hyper-V cluster to a new Hyper-V cluster. On the old cluster we’ve deployed a two node Sophos UTM9 HA cluster. It’s running fine for years now. During the migration, I’ve shutdown the slave node and migrated it to the new Hyper-V cluster. This all went without issues. However as soon as I booted the slave and it came online, it started complaining about another slave being around and started ‘loosing’ heartbeats:
2017:10:19-21:16:21 fw-1 ha_daemon[28614]: id="38A0" severity="info" sys="System" sub="ha" seq="M: 35 21.210" name="Reading cluster configuration" 2017:10:19-21:16:26 fw-1 ha_daemon[28614]: id="38A0" severity="info" sys="System" sub="ha" seq="M: 36 26.096" name="Set syncing.files for node 2" 2017:10:19-21:16:35 fw-2 ha_daemon[6547]: id="38A1" severity="warn" sys="System" sub="ha" seq="S: 99 35.855" name="Lost heartbeat message from node 1! Expected 724 but got 723" 2017:10:19-21:16:36 fw-1 ha_daemon[28614]: id="38A0" severity="info" sys="System" sub="ha" seq="M: 37 36.251" name="Monitoring interfaces for link beat: eth5 eth4 eth2 eth3 eth6 eth0" 2017:10:19-21:16:36 fw-2 ha_daemon[6547]: id="38A1" severity="warn" sys="System" sub="ha" seq="S: 100 36.856" name="Lost heartbeat message from node 1! Expected 725 but got 724" 2017:10:19-21:16:36 fw-2 ha_daemon[6547]: id="38A1" severity="warn" sys="System" sub="ha" seq="S: 101 36.938" name="Another slave around!" 2017:10:19-21:16:37 fw-2 ha_daemon[6547]: id="38A0" severity="info" sys="System" sub="ha" seq="S: 102 37.048" name="Reading cluster configuration" 2017:10:19-21:16:37 fw-2 ha_daemon[6547]: id="38A0" severity="info" sys="System" sub="ha" seq="S: 103 37.049" name="Starting use of backup interface 'eth0'" 2017:10:19-21:16:37 fw-2 ha_daemon[6547]: id="38A1" severity="warn" sys="System" sub="ha" seq="S: 104 37.857" name="Lost heartbeat message from node 1! Expected 726 but got 725" 2017:10:19-21:16:37 fw-2 ha_daemon[6547]: id="38A1" severity="warn" sys="System" sub="ha" seq="S: 105 37.939" name="Another slave around!" 2017:10:19-21:16:38 fw-2 ha_daemon[6547]: id="38A1" severity="warn" sys="System" sub="ha" seq="S: 106 38.858" name="Lost heartbeat message from node 1! Expected 727 but got 726" 2017:10:19-21:16:39 fw-2 ha_daemon[6547]: id="38A1" severity="warn" sys="System" sub="ha" seq="S: 107 39.859" name="Lost heartbeat message from node 1! Expected 728 but got 727" 2017:10:19-21:16:39 fw-2 ha_daemon[6547]: id="38A1" severity="warn" sys="System" sub="ha" seq="S: 108 39.941" name="Another slave around!" 2017:10:19-21:16:40 fw-2 ha_daemon[6547]: id="38A1" severity="warn" sys="System" sub="ha" seq="S: 109 40.860" name="Lost heartbeat message from node 1! Expected 729 but got 728" 2017:10:19-21:16:41 fw-2 ha_daemon[6547]: id="38A1" severity="warn" sys="System" sub="ha" seq="S: 110 41.861" name="Lost heartbeat message from node 1! Expected 730 but got 729" 2017:10:19-21:16:41 fw-2 ha_daemon[6547]: id="38A1" severity="warn" sys="System" sub="ha" seq="S: 111 41.943" name="Another slave around!" 2017:10:19-21:16:42 fw-2 ha_daemon[6547]: id="38A0" severity="info" sys="System" sub="ha" seq="S: 112 42.088" name="Monitoring interfaces for link beat: eth5 eth4 eth2 eth3 eth6 eth0" 2017:10:19-21:16:42 fw-2 ha_daemon[6547]: id="38A1" severity="warn" sys="System" sub="ha" seq="S: 113 42.863" name="Lost heartbeat message from node 1! Expected 731 but got 730" 2017:10:19-21:16:42 fw-2 ha_daemon[6547]: id="38A1" severity="warn" sys="System" sub="ha" seq="S: 114 42.944" name="Another slave around!"
Ok, so that’s weird. I know there’s lots of networking between the old and new Hyper-V cluster, however that could only explain the ‘lost heartbeat’ messages and not the ‘Another slave around’ message. So what’s going on? In an attempt of resolving the issue right on the spot, I disabled HA on the master which resulted in the slave being factory reset. I thought there might be a flipped bit. But even after rebuilding the cluster and the same issue appeared. Eventually we migrated the slave back to the old Hyper-V cluster. Guess what: problem ‘solved’. Within 5 minutes the slave was in sync with the master and no weird error messages.
I contacted Sophos support and they said it all just should work. To mention: the new Hyper-V cluster has the same OS/Hyper-V version as the old cluster, only newer hardware.
I’ve been debugging this for two weeks and finally a break through: turns out the only other difference between both Hyper-V clusters is the way nic teaming is configured. The old Hyper-V cluster is using LACP, the new cluster Switch independent with Load balancing mode ‘Dynamic’.
Since Sophos HA is using multicast broadcasts those leave one physical nic and since it’s a broadcast the switch backend also sends it to the second team nic. This causes the HA heartbeat message to re-enter the UTM node which send it causing it to think it’s from another Sophos UTM node. Apparently Sophos HA has no way (or it simply doesn’t) to check if the heartbeat message originated from itself.
I confirmed this by deploying a brand new Sophos UTM node to the new Hyper-V cluster. As soon as I turned on HA, it started complaining is was seeing another master. Well that’s odd since this VM was completely isolated in it’s own VLANs.
2017:10:24-13:50:25 fw-testing-1 ha_daemon[4315]: id="38A1" severity="warn" sys="System" sub="ha" seq="M: 49 25.428" name="Another master around!" 2017:10:24-13:50:25 fw-testing-1 ha_daemon[4315]: id="38A0" severity="info" sys="System" sub="ha" seq="M: 50 25.428" name="Enforce MASTER, Resending gratuitous arp" 2017:10:24-13:50:25 fw-testing-1 ha_daemon[4315]: id="38A0" severity="info" sys="System" sub="ha" seq="M: 51 25.428" name="Executing (nowait) /etc/init.d/ha_mode enforce_master" 2017:10:24-13:50:25 fw-testing-1 ha_daemon[4315]: id="38A1" severity="warn" sys="System" sub="ha" seq="M: 52 25.428" name="master_race(): other MASTER with the same solution = 0" 2017:10:24-13:50:25 fw-testing-1 ha_daemon[4315]: id="38A0" severity="info" sys="System" sub="ha" seq="M: 53 25.428" name="Enforce MASTER, Resending gratuitous arp" 2017:10:24-13:50:25 fw-testing-1 ha_daemon[4315]: id="38A0" severity="info" sys="System" sub="ha" seq="M: 54 25.428" name="Executing (nowait) /etc/init.d/ha_mode enforce_master" 2017:10:24-13:50:25 fw-testing-1 ha_mode[6624]: calling enforce_master 2017:10:24-13:50:25 fw-testing-1 ha_mode[6622]: calling enforce_master 2017:10:24-13:50:25 fw-testing-1 ha_mode[6622]: enforce_master: waiting for last ha_mode done 2017:10:24-13:50:25 fw-testing-1 ha_mode[6622]: enforce_master 2017:10:24-13:50:25 fw-testing-1 ha_mode[6622]: /var/mdw/scripts/confd-sync: /usr/local/bin/confd-sync stopped 2017:10:24-13:50:25 fw-testing-1 ha_mode[6622]: /var/mdw/scripts/confd-sync: /usr/local/bin/confd-sync started 2017:10:24-13:50:25 fw-testing-1 ha_mode[6622]: enforce_master done (started at 13:50:25) 2017:10:24-13:50:25 fw-testing-1 ha_mode[6624]: enforce_master: waiting for last ha_mode done 2017:10:24-13:50:25 fw-testing-1 ha_mode[6624]: enforce_master 2017:10:24-13:50:25 fw-testing-1 ha_mode[6624]: /var/mdw/scripts/confd-sync: /usr/local/bin/confd-sync stopped 2017:10:24-13:50:26 fw-testing-1 ha_mode[6624]: /var/mdw/scripts/confd-sync: /usr/local/bin/confd-sync started 2017:10:24-13:50:26 fw-testing-1 ha_mode[6624]: enforce_master done (started at 13:50:25)
As soon as I disabled a nic from the team interface, the errors stopped. This confirmed my believe that it was receiving its own heartbeats and thought they were from another master.
I re-enabled the nic and reconfigured the nic teaming to use load balancing mode ‘Hyper-V Port’. Et voila – problem solved. No more duplicate node messages. Then I added the test slave to the cluster and still no ‘another master / slave’ message.
So even though the Microsoft Recommended nic teaming settings are ‘Switch independent’ and ‘dynamic’ (src: Windows Server 2012 R2 NIC Teaming User Guide, page 12), as long Sophos UTM HA has no clue which heartbeat messages are send by itself and you’re running a Sophos UTM cluster on Hyper-V you’re better off setting the load balancing mode to ‘Hyper-V port’. Else you won’t get your Sophos UTM cluster stable or even in-sync.
Used info:
Windows Server 2012 R2 NIC Teaming User Guide – https://gallery.technet.microsoft.com/Windows-Server-2012-R2-NIC-85aa1318#content














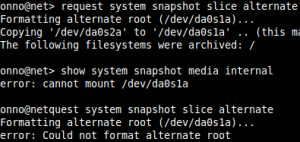 This week I encountered this error for the first time in the years I’m working with JunOS now. Last week I installed two SRX’s at a remote datacenter location in NJ, US. All working fine and once back in my home country I added some monitoring checks to the devices and thought, well lets sync the JunOS alternate partition with the primary. This went just fine:
This week I encountered this error for the first time in the years I’m working with JunOS now. Last week I installed two SRX’s at a remote datacenter location in NJ, US. All working fine and once back in my home country I added some monitoring checks to the devices and thought, well lets sync the JunOS alternate partition with the primary. This went just fine:



























